

 蛙本
蛙本音楽配信をしたので、MVを作ってみたい。
ずっと頭のなかにイメージだけはあったものの、「実写でちゃんと撮る」のはスタジオ代や日程調整、天気の都合など、現実的なハードルが高すぎました。
だったら一度、実写は脇に置いておいて。
今の自分でも手を動かせるところから始めてみようと思い、AIを総動員してMVづくりに挑戦してみました。
結果としては、構想から完成まで約1週間。
途中で何度も「おいーー!」と叫びたくなる場面はありつつも、なんとか1本のMVとして形にすることができました。
この記事では、
- どんな世界観・キャラクターで作ったのか
- 画像生成〜動画生成〜編集まで、具体的にどう進めたのか
- 使ってみてわかった各AIツールの得意・不得意
- 実際に作ってみての反省点や学び
あたりを、備忘録もかねてまとめておきます。
AIでMVを作るはじめの一歩

最初にあったのは、1本のMVというより、ぼんやりした世界観のイメージでした。
- 舞台は無人の遊園地
- 夢か現実かはわからない
- 女の子が迷い込んで、ヤギ人間とヒツジ人間に出会う
このイメージをまずGeminiに渡して、ざっくりした雰囲気のイラストを何枚か出してもらいました。

ここではまだ「使える素材を作る」というより、「頭の中を可視化してもらう」感覚に近いです。
雰囲気が掴めてきたところで、登場人物を3人に固定しました。
- 女の子:遊園地に迷い込む主人公(名前はGPTがつけてくれた「ナギちゃん」)
- ヤギ男:ヤギの頭+人間の身体。スーツ姿でワインレッドのネクタイ
- ヒツジ男:ヒツジの頭+人間の身体。スーツ姿でブルーのネクタイ
この3人を軸に、「無人の遊園地で、彼らが静かに出会うMV」を目指すことにしました。
キャラクターデザイン:Midjourney×Nanobanana(Gemini)

主人公になる女の子のビジュアルは、Midjourney+ChatGPTにかなりお任せしました。
僕の中で決まっていたのは、
- 日本人
- 髪型はボブ(僕が好きだから)
この程度だったので、あとはGPTにプロンプト作りをお願いして、Midjourneyに投げていきます。
何パターンか出してもらううちに、「この子だな」という顔が1枚、すっと決まりました。
そこから服装についてもGPTと相談。
- どんな服なら世界観に合うか
- 色味はどのトーンがいいか
などを対話しながら決めていき、最終的な「ナギちゃん像」を固めました。
Nanobanana(Gemini)でキャラクターの一貫性を保つ

ここからがGeminiのNanobananaが本領発揮したところです。
Midjourneyで作ったナギちゃんの顔画像をNanobananaに渡し、
蛙本この子に◯◯を着させて
とお願いすると、顔の一貫性を保ったまま服装違いの画像を作ってくれます。
これが想像以上に便利でした。

さらに、
- 正面
- 横
- 後ろ
- 顔のアップ
といった要素を1枚にまとめたキャラクターシートもNanobananaに作ってもらいました。

こういうシートがあると、あとから別のポーズやシーンを作るときにも一貫性が保ちやすくなります。
とはいえ、今になって振り返ると、
- キャラシート内で、全身の顔とアップの顔の雰囲気が若干ズレている
- もう少し「決め顔」を固めてから量産に入ればよかった
という反省もあります。
「なんかちょっと違うけど、まあいっか」で進めると、後半でジワジワ効いてきますね‥‥。
ヤギ男・ヒツジ男とメリーゴーランドなどキー背景の作る

ナギちゃんのフローが見えたので、ヤギ男・ヒツジ男も同じやり方で作りました。
- Midjourneyでベースとなるビジュアルを作成
- Nanobananaでキャラクターシートを作成
- 必要に応じて服装違いやポーズ違いを追加
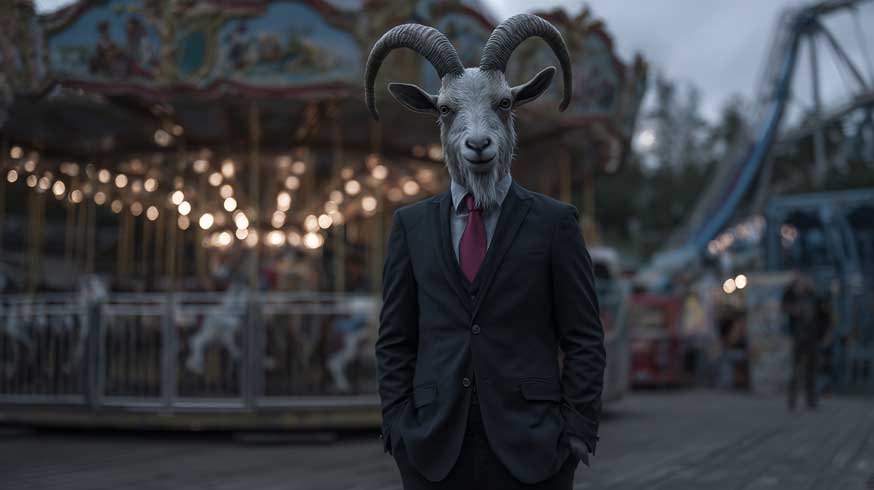
さらに、MVの中で「キーになる絵」として、メリーゴーランドのシーンもMidjourneyに生成してもらいました。
- 木馬の代わりにヤギとヒツジのデザイン
- 遊園地の外観も、ヤギ&ヒツジモチーフで
といった無茶振りも、Midjourneyは応えてくれました。
絵コンテ代わりのテキストコンテでMV全体を組み立てる

MVづくりをちゃんとやるなら、たぶん絵コンテを描くべきなんでしょうが、
今回はテキストベースのざっくりしたコンテで進めました。
- 1番:こういう流れで
- サビ:ここはこのシーンの連続で
- 2番:ここで場所を移動して…
といった感じで、文章だけでストーリーラインを書き出しておきます。
正直、AIで思い通りの映像を出すのは難しいかなと思っていたので、きっちり決め込んでも、そのとおりには出てこないだろうという諦めもありました。
なので、大きな流れだけ決めて、あとは手を動かしながら微調整くらいの温度感で進めていきました。
Nanobananaで必要なシーンの静止画を量産する

構成がざっくり固まったら、あとはひたすらにNanobananaでシーン画像を量産するフェーズです。
- ナギちゃんとヤギ男、ヒツジ男がメリーゴーランドの前に立っている
- ナギちゃんとヒツジ男が観覧車の前のベンチに座っている
- ナギちゃんとヤギ男とヒツジ男が夕暮れの遊園地を奥に向かって歩いていく
など、頭の中にあるシーンを1枚ずつラフに出していきます。
この段階では、
- とにかく必要そうなカットを出し切る
- 細部の違和感はあまり気にしない(場合によってはPhotoshopで自分で直す)
- 後で「使える/使えない」を編集で決める
くらいの雑さで量を出したほうが、最終的には楽でした。
静止画から動画へ:DomoAI / VEO3 /Klingの役割分担
DomoAIのカオス

静止画がある程度揃ったところで、次は動画生成AIの出番です。
最初に使ったのはDomoAIでした。
選んだ理由は、
- リップシンクが強いという前評判
- プランによっては「リラックスモード」でクレジット消費なしに何度も生成できる
という点です。
リップシンクをやりたいというのは、今回のMVの中でポイントでもありました。
ところが、ここでなかなかのカオスが始まります。
遊園地の画像を使ってDomoAIで動画生成をすると、
- 「無人の遊園地にして」と言っても、なぜか人を追加してくる
- 広い道路に車を走らせる
- ジェットコースターのレールの上を車が走っている
- ナギちゃんは無表情でいてほしいのに、全力でニコニコさせてくる
- ナギちゃんは笑顔で手を振る
と、こちらの指示を完全に無視した「陽キャMV」が量産されるという事態に。
「これもう、人がいる遊園地のMVでいいのでは‥‥?」と一瞬心が折れかけつつも、DomoAIの運がよければ良いのが出来るというガチャ状態。
半分ヤケクソでガチャを回し続け、使えるカットを拾っていきました。
リップシンクの部分はどうやってもうまく行かなかったので、完成版では無機質な場所でナギちゃんは歌っているのです。
VEO3でメリーゴーランドなど構造のあるシーンを生成する

僕のGeminiアカウントでは、1日3回だけVEO3も使えました。
そこで、DomoAIとVEO3を併用しつつメリーゴーランドのシーンなどを作っていきました。
VEO3に関しては、
- メリーゴーランドの「構造」をちゃんと理解している感じがする
- ヤギ&ヒツジの木馬が、上下しながら回転する様子を自然なスピードで出してくれる
という点にかなり感激しました。
DomoAIだと、やたら高速回転したり、逆回転したりと、なかなか落ち着いてくれなかった部分が、VEO3では「あ、ちゃんと遊園地にあるやつだ」という動きになっていたのが印象的でした。
Klingでプロンプト通りのAI動画を狙い撃ちする

それでもDomoAIの「言うことを聞かない問題」はなかなか解消されません。
人を出す、車を走らせる、テーマと違う方向へ持っていこうとする‥‥。
そこで、別の動画生成AI「Kling」を試してみることにしました。
最初は無料枠で少し触ってみたのですが、
「え、プロンプト通りにちゃんと作ってくれる‥‥!」
と、ちょっと感動するレベルで指示に忠実でした。
さすがにお金の問題もあるので、一番下のプランで契約し、
「ここぞ」というカットだけKlingに任せるという使い分けにしました。
- DomoAI
- 長所:リップシンクが表情豊かで強い。リラックスモードで数撃てる。
- 短所:無人にしたいのに人を出してくるなど、テーマから暴走しがち。
- Kling
- 長所:プロンプトに忠実で狙い撃ちがしやすい。
- 短所:クレジット制なので「ここぞ」というカットに絞る必要あり。
最終的に、「リップシンクはDomoAI」「コントロールしたいシーンはKling」という棲み分けに落ち着きました。
Premiere Proで1本のをMVとしていく

動画の素材が集まってきたら、Adobe Premiere Proで編集していきます。
最初にやりがちだったのは、
- 音のキリがいいところで必ずカットを切りたくなる
- ドラムやキメに合わせて映像をパンパン切り替えたくなる
という、「音に映像を全部ハメにいく」編集でした。
もちろん、イントロ→Aメロ、Aメロ→サビといった大きな区切りでは音に合わせて映像を切り替えるほうが気持ちいいです。
一方で、それ以外の箇所ではあえて、
- 音に合わせないカットチェンジ
- 少しだけ「ズレた」ところで映像を切り替える
といった編集を心がけました。
そうしないと、テンポだけ早くて安っぽいMVになりそうだなと感じたためです。
テキストコンテに合わせてだいたいの流れを並べてみて、
「ここ、もうちょっと尺欲しいな‥‥」「こういうカットが1枚あればつながりやすいな」
と思ったところで、その都度また 画像生成→動画生成に戻る、という行ったり来たりを繰り返しました。
細部を詰める:マスク処理やシーンの作り直し

ラフに並べた段階で、体感としては2日くらいで8割は完成しました。
ただ、ここからが長かったです。
はじめにDomoAIで進めていったので、よく見ると背景の遠くに人が歩いているといった細かい違和感がどんどん目につきはじめます。
そこから、
- After EffectsやPremiereでマスクをかけて人を隠す
- 一部のシーンをまるごと生成し直す
- 別のAIツールで作り直したカットに差し替える
といった細かい修正を積み重ねて、
最終的には約1週間ほどで完成というスケジュールになりました。
(まあ、完成版でも実はよく見ると人が歩いているシーンはあるんですが‥‥)
実際にAIでMVを作ってみてのわかったこと

今回のチャレンジで感じたことをざっくりまとめると、こんな感じです。
初めてでも意外とMVは作れる
ただし、紙芝居的にならないようにするためには、カメラワークや「起点となる絵のアングル」の工夫が必要。
DomoAIのリップシンクはとても表情豊かで良い
Klingでもリップシンクはできますが、少なくとも今回はDomoAIのほうが「表情」が豊かで、歌っている感じが強く出ました。
Klingはプロンプトに忠実でコントロールしやすい
欲しい画をピンポイントで狙いにいくときに、とても頼りになりました。
DomoAIはプロンプトよりも「絵の世界観」に引っ張られる感じ
いい意味でも悪い意味でも、元の絵の雰囲気を優先して暴走(?)してくることが多かったです。
ツールの「使い分け」がかなり重要
1つのAIで全部やろうとせず、「得意なところだけやってもらう」と割り切ると前に進みやすい。
本気で作るなら、やっぱり映像の知識は必要
カット割り、カメラワーク、光や色の扱いなど、「AIがあるからなんとかなる」部分と「人間側の知識がないとどうにもならない」部分の差を強く感じました。
まとめ:AI時代のMVづくりでいちばん楽しいところ
実写でMVを撮るとなると、どうしても大掛かりな準備が必要で、構想だけが頭の中に溜まっていきがちでした。
今回はAIをフル活用したおかげで、
- 頭の中にあった「無人の遊園地」のイメージを
- キャラクターと世界観のある映像として
- 1週間ほどで最後まで作り切る
という経験ができました。
もちろん、プロのMVと比べたら粗いところだらけです。
それでも 「自分の中の物語を、ちゃんと1本の作品として外に出せた」という意味では、とても満足しています。
今はいろんなツールがあるので、そういうAIに全部丸投げしてしまえば、もっと早くそれっぽい映像は作れたのかもしれません。
でもそれだと「これ、自分がやる意味あったっけ?」という気持ちにもなりそうで、
今回に関しては、世界観やカット割りといった「何を見せたいか」は自分で決めて、その実現をAIに手伝ってもらう、というスタンスを大事にしました。
これからAIツールはもっと増えるし、精度も上がっていくはずです。
でも結局のところ、
- どんな世界を見せたいのか
- そのために、どのツールをどう組み合わせるのか
を考えて、地道に手を動かしていく作業そのものが、いちばん楽しかったりします。
また別の世界観でも、AIたちと一緒にMVを作ってみようと思います。

